? How to Measure Brand Share in AI Answers — GEOly AI glossary cover")
Share of Model(SoM,模型份额)指在一组固定的品类 prompts 和 AI 引擎范围内,AI 生成回答中属于你品牌的提及次数占全部品牌提及次数的百分比。假设 ChatGPT、Gemini、Perplexity 在回答 1,000 条购买意图 prompts 时共产生 5,000 次品牌提及,其中 1,200 次提到你,你的 Share of Model 就是 24%。它是 GEO(生成引擎优化)时代的市场份额指标:Share of Voice 衡量广告声量,Share of Search 衡量搜索需求,而 SoM 衡量的是 AI 模型真正把你的品牌写进回答的频率。
核心要点
- 计算公式:SoM =(你品牌在 AI 回答中的提及次数 ÷ 全部品牌提及次数)× 100,且必须锁定同一组 prompts、同一批引擎、同一时间窗口。
- SoM 是相对指标:它回答的是「AI 对话里你占多大份额」,而不是「你是否出现」——后者是提及率,属于另一类 AI 可见性指标。
- 只数提及次数会漏掉三件事:品牌在回答中的位置、情感倾向、以及引擎是否引用了你的页面。
- LLM 输出每次运行都会波动,单次测量只是噪声。可靠的 SoM 来自按固定节奏重复运行同一组 prompts,看趋势线。
- 提升 SoM 的路径与所有 GEO 目标一致:清晰的实体信号、进入模型信任的引用源、以及「答案形态」的内容。
从 Share of Voice 到 Share of Model
每个营销时代都有自己的主导指标。大众媒体时代看 Share of Voice:你在品类广告声量中占多少。Google 时代加上了 Share of Search:品类搜索量中有多少指向你,这是需求的可用代理。Share of Model 是 AI 时代的接棒者,但它回答的是另一个问题——不是你的声音多大,也不是多少人主动搜你,而是当用户面前根本没有结果页时,模型推荐你的频率有多高。
这个转变之所以重要,是因为漏斗本身搬家了。Gartner 曾预测传统搜索量到 2026 年会因用户转向 AI 助手而下降 25%,而如今购买调研常常直接终结在回答内部——也就是零点击搜索的逻辑。当消费者问「敏感肌用哪款物理防晒最好」,然后照着返回的三个品牌下单时,这份短名单就是市场本身。SoM 就是你在其中的那一块。
Share of Model 怎么计算
基础公式:SoM =(你品牌的提及次数 ÷ AI 回答中的全部品牌提及次数)× 100。
举个例子。你卖 CRM 软件,定义了 1,000 条品类 prompts——「小团队最好用的 CRM」「HubSpot 替代品」「免费额度实用的 CRM」——在目标引擎上全部跑一遍。回答中共出现 5,000 次品牌提及,其中 1,200 次是你的产品,你的 Share of Model 就是 24%。
三个进阶维度,决定 SoM 是实用指标还是虚荣数字:
- 位置。第一个被点名的品牌,权重远高于结尾「其他选择还有」里的一笔带过。按位置加权的 SoM 比平铺计数更贴近真实购买行为。
- 情感。「很流行但偏贵」和「性价比首选」都算一次提及。应当在计数之外同步做 AI 情感分析。
- 引用。当引擎把你的域名列为信源时,你同时获得引荐流量和不断累积的权威度。AI 引用要作为独立比率单独追踪。
还有两条测量纪律。第一,锁死 prompts 集合、引擎组合和时间窗口,因为 SoM 数字只能和它自己比。第二,反复采样:同一条 prompt 每次可能返回不同的品牌列表,只有按计划重复运行,噪声才会变成趋势线。
为什么 2026 年 Share of Model 如此重要
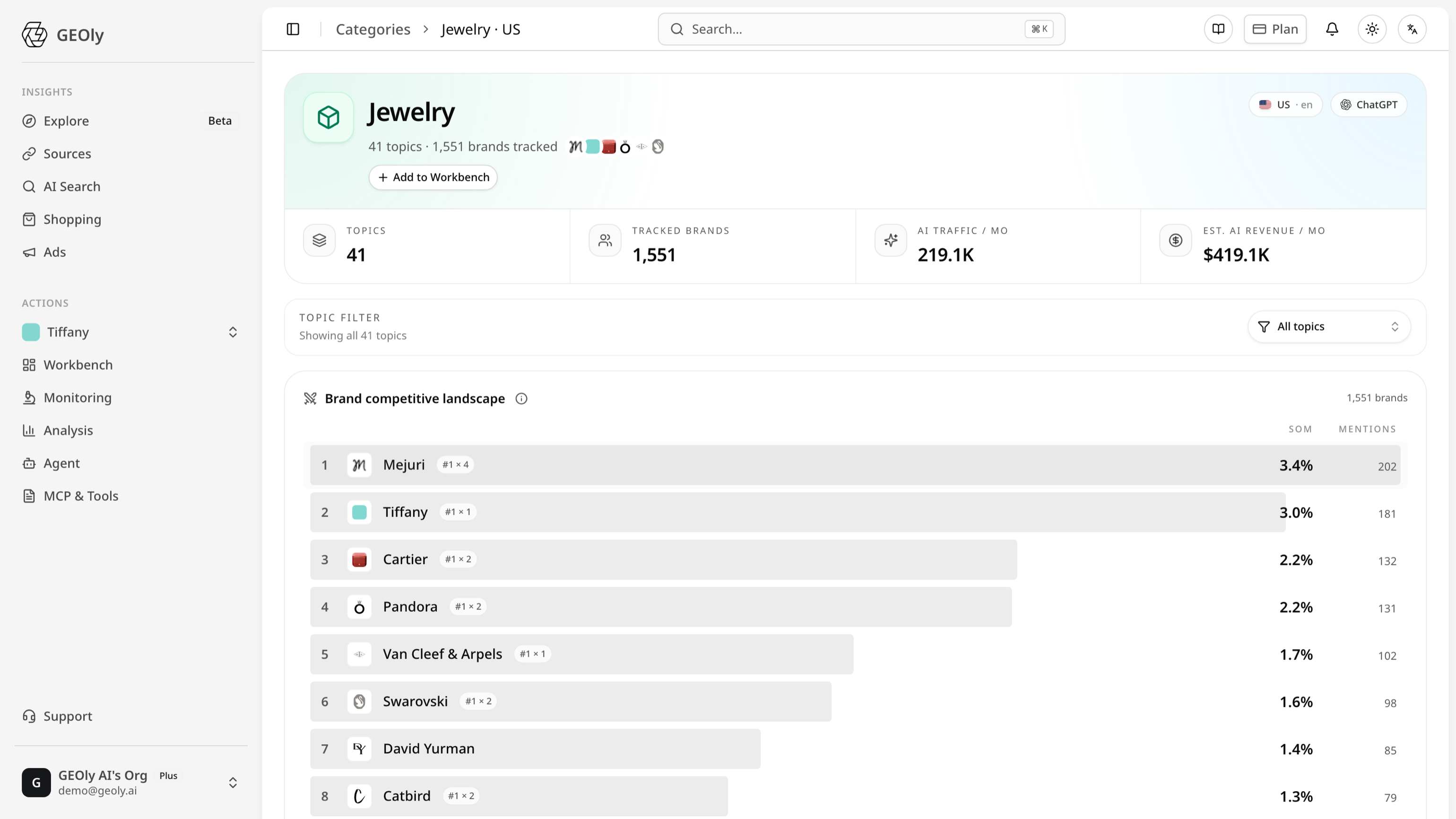
AI 回答让注意力更集中。一张结果页有十个自然位,而一条 AI 回答通常只点名三到五个品牌。GEOly 的行业数据在各品类反复呈现同一格局:少数品牌吃掉绝大多数提及,长尾品牌在对话中干脆不存在。

")
")
")