
GEO 竞争分析,是量化 AI 引擎推荐竞争对手而非你的频率、它们为何这样描述对手,以及哪些信源在"喂养"这些推荐——好让你有针对性地缩小差距。它越过外链和关键词,直接看 ChatGPT、Gemini、Perplexity 真正生成的答案:谁被点名、以什么顺序、被贴上什么形容词、又引用了谁。做到位,你就不再猜"谁是对手",而是清楚看到在哪些 prompt 上竞品垄断了推荐位、以及要把它挤下来需要做什么。
这件事之所以关键,是因为买家常常根本不会到你的网站。当助手说"耐用选 A 品牌,预算紧就选 B 品牌",没出现在这句话里的品牌,在任何点击发生之前就已经出局。常规的 GEO 工作让你进入答案;竞争分析告诉你,你在争夺这个推荐位时的对手到底是谁。
关键要点
- 你的 AI 竞争对手,是模型在答案里点名的那些品牌——往往不是你的 Google 对手——所以第一步是搞清楚谁真的会出现。
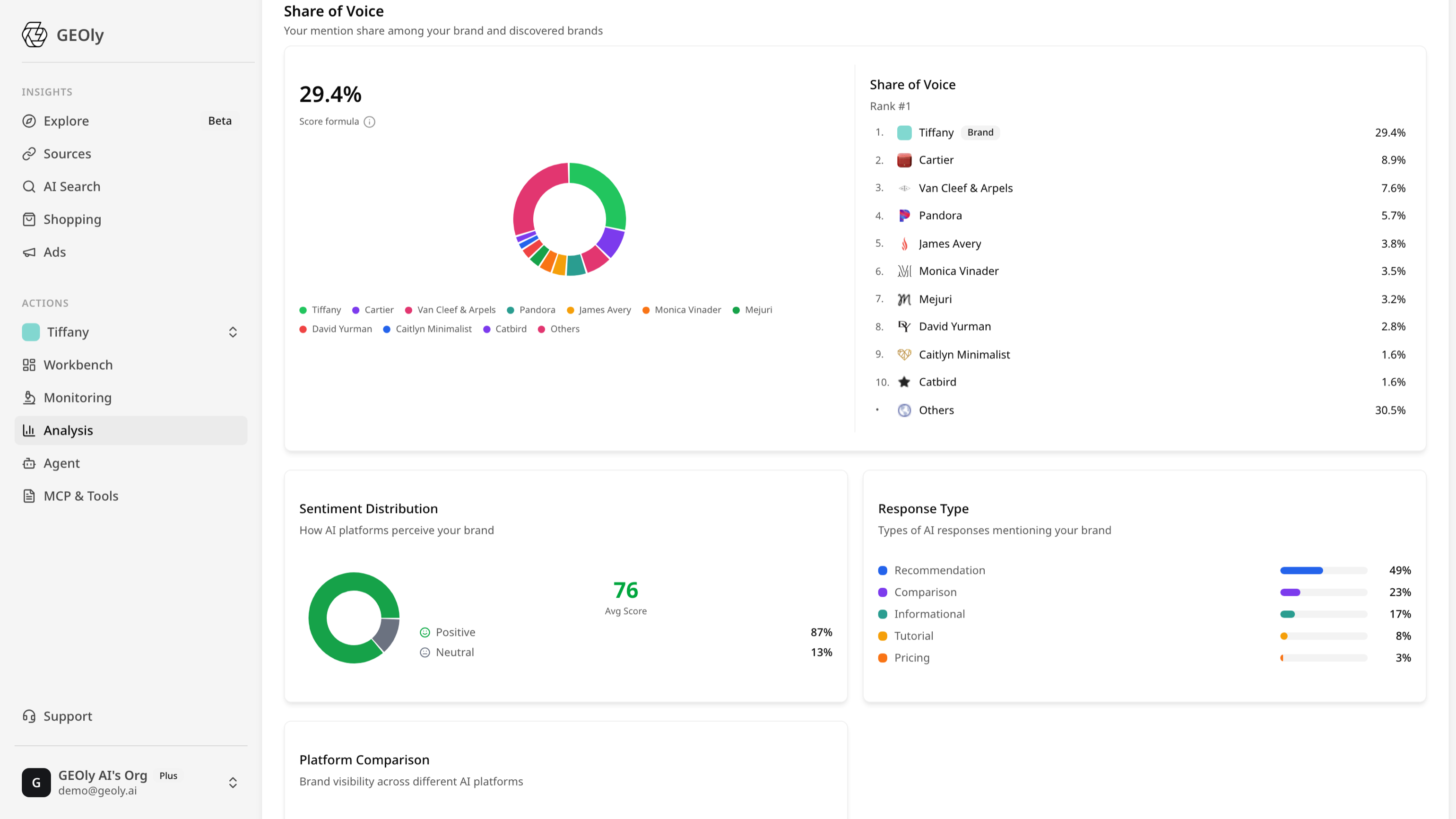
- Share of Model(SoM)把差距变成数字:对手 45% 对你 10%,这个意图就被它占据,差值就是你的目标。
- 引用信源就是你的触达路线图;支撑竞品提及的那些第三方页面,就是你要去争取曝光的清单。
- 表述框架本身就是战场——模型给对手贴的形容词("实惠""复杂""高端")是一个你可以攻击或绕开的定位。
- 要跨全部 7 大引擎测量,因为一个品牌可能在 Perplexity 上占尽优势,却在 ChatGPT 里完全隐形。
为什么 GEO 竞争分析不一样
SEO 工具读的是网页,读不到模型说了什么。要看清对手的 AI 可见性,你得改变测量的三件事。
从关键词到 prompt。搜索量被 prompt 覆盖度取代——竞品在买家真正问助手的问题里出现的频率,而不是他们在搜索框里敲的词。一个高意图 prompt,比如"最适合[某场景]的[品类]",可能比一千个长尾关键词更重要。
从排名到 Share of Model。聊天答案没有第二页。你要么在推荐集合里,要么不在。Share of Model 衡量的是你相对竞品、在成千上万条生成答案中的存在度——这是 AI 时代最接近"声量份额"的东西。
从外链到引用。不再数链接,而是追踪引擎在谈论竞品时到底从哪些信源取材。Citation 分析 能看出一个对手是靠自家文档、一条 Reddit 讨论,还是某家大媒体的评测赢得推荐。
四步工作流
1. 找出你真正的 AI 竞争对手
你的 AI 对手,常常不是你的 SEO 对手。跨引擎跑一组发现型 prompt——"对比排名靠前的[品类]方案""[你的品牌]有哪些替代品""最适合[某类买家]的[品类]"——把每一个被点名的品牌都记下来。
在 GEOly 里,行业级数据库在品类层面就做了这件事:它呈现模型共同收敛出的品牌榜单,让你像助手那样看这组同行,而不是像你的营销 PPT 想象的那样。反复跨引擎出现的品牌,就是你真正的对手。
2. 读懂"共识叙事"
存在只是一半,表述框架是另一半。留意模型顺手用的形容词和一句话描述。如果一个对手总是"实惠之选",另一个总是"高端首选",模型就已经为它们各自建立了一套共识叙事——在买家心智里占了一个会被反复重复的位置。
这套叙事是一张"空位地图"。如果所有竞品都是"高端",那么"最创新"或"最适合某细分"也许还没被占领,你可以有意识地朝它建设。GEOly 的品牌感知视图把这种框架跨引擎聚合起来,让你读到的是一种模式,而不是某一次侥幸的答案。
3. 追踪引用信源
当 Perplexity 或 Google AI Overviews 推荐某个竞品时,把信源点开。模型是在倚重对手自家的博客、一个对比站、一条 Reddit 或论坛帖,还是一篇行业评测?

每一个反复出现的域名,都是你触达路线图上的一行。如果某个评测站或社区帖在支撑竞品的提及,去那里争取到你自己的存在,是 GEO 里杠杆最高的动作之一——你改的是模型的素材来源,而不只是你自己的页面。
4. 用 Share of Model 量化差距
把画面变成数字。在同一组 prompt 上,算出你和每个对手的 SoM,语义差距就一目了然:对手 45% 对你 10% 不是四舍五入的误差,而是一个可以量化、可以据此排兵布阵的结构性领先。
GEOly 会把 SoM 与提及率、引用率,以及 0–100 的 AIGVR(AI-Generated Visibility Rate)可见性分数一起报告,让你和每个竞品都落在同一根轴上,看差距随时间拉大还是收窄。再配一次完整的 ,就能看出是哪些可修复的问题在压低你自己的分数。
 — GEOly AI GEO guide cover")
 — GEOly AI GEO guide cover")
