
AI 时代的品牌声誉管理,管的是用户问「这个品牌靠谱吗」时,引擎合成出来的那一段答案——而做法不是把链接埋掉,而是改变模型读取的信源。实操就是三步循环:监测 ChatGPT、Gemini、Perplexity 到底怎么描述你;纠正它们检索到的事实;再用足量新鲜、权威的内容,把模型的「共识」重新写向对你有利的方向。过去二十年,网络声誉管理(ORM)等于把一条差评从 Google 首页挤到第二页。这个杠杆已经失效——当答案是一段话而不是十条蓝色链接时,根本没有「第二页」可以藏。
Key takeaways
- AI 声誉管理,是用「信源控制」取代「排名压制」:你无法把差结果降权,只能改变模型合成答案时读到的数据。
- 引擎对你品牌的看法来自三层——训练数据、实时检索(RAG)、系统提示词。只有检索这一层,是你本季度就能撬动的。
- 先测量再行动:用 AIGVR 与 Share of Model 等指标,跨引擎追踪形容词、情感倾向和推荐占比。
- 结构化事实赢面更大。一份干净的 Organization schema、及时更新的 About/维基百科/Crunchbase 资料,加上 FAQ 标记,能减少绝大多数负面覆盖背后的「幻觉」。
- UGC 权重极高。一条 Reddit 或 Trustpilot 帖子,就可能决定引擎如何回答「[Brand] 靠不靠谱」。
从「压制搜索结果」到「合成答案」
传统搜索里,用户读多个来源、自己形成判断。在 AI 搜索里,判断往往是被喂给他的。问引擎某个品牌可不可靠,你拿到的是一句合成好的结论——情感、关键事实和联想,被压缩进几句话。
这段结论有三个值得点名的成分:
- 情感——这个品牌总体上被信任还是被质疑?
- 事实——它卖什么、归谁所有、在哪运营。
- 联想——围绕它聚集的词:「高端」「骗局」「创新」「发货慢」。
这正是从搜索时代优化,转向 Generative Engine Optimization 的分水岭:你争的不再是一个排名,而是能不能成为答案的一部分。
引擎是怎么形成对你品牌的看法的
模型没有情绪,它只是镜像它能看到的文本的情感。喂给这面镜子的有三层。
- 训练数据——基座模型学习过的历史语料,通常滞后一年甚至更久。
- 检索(RAG)——引擎为回答当下问题,从实时网络拉取的新鲜页面。Perplexity、Google AI Mode 与 AI Overviews、Copilot、ChatGPT search 都在这么做。
- 系统提示词——那些让模型「有用、无害、诚实」的隐藏指令。
训练数据你改不了,系统提示词你碰不到。检索是你真正拥有的那一层——引擎今天查你时找到的新鲜内容。声誉工作,几乎全部都是检索工作。
四步打法
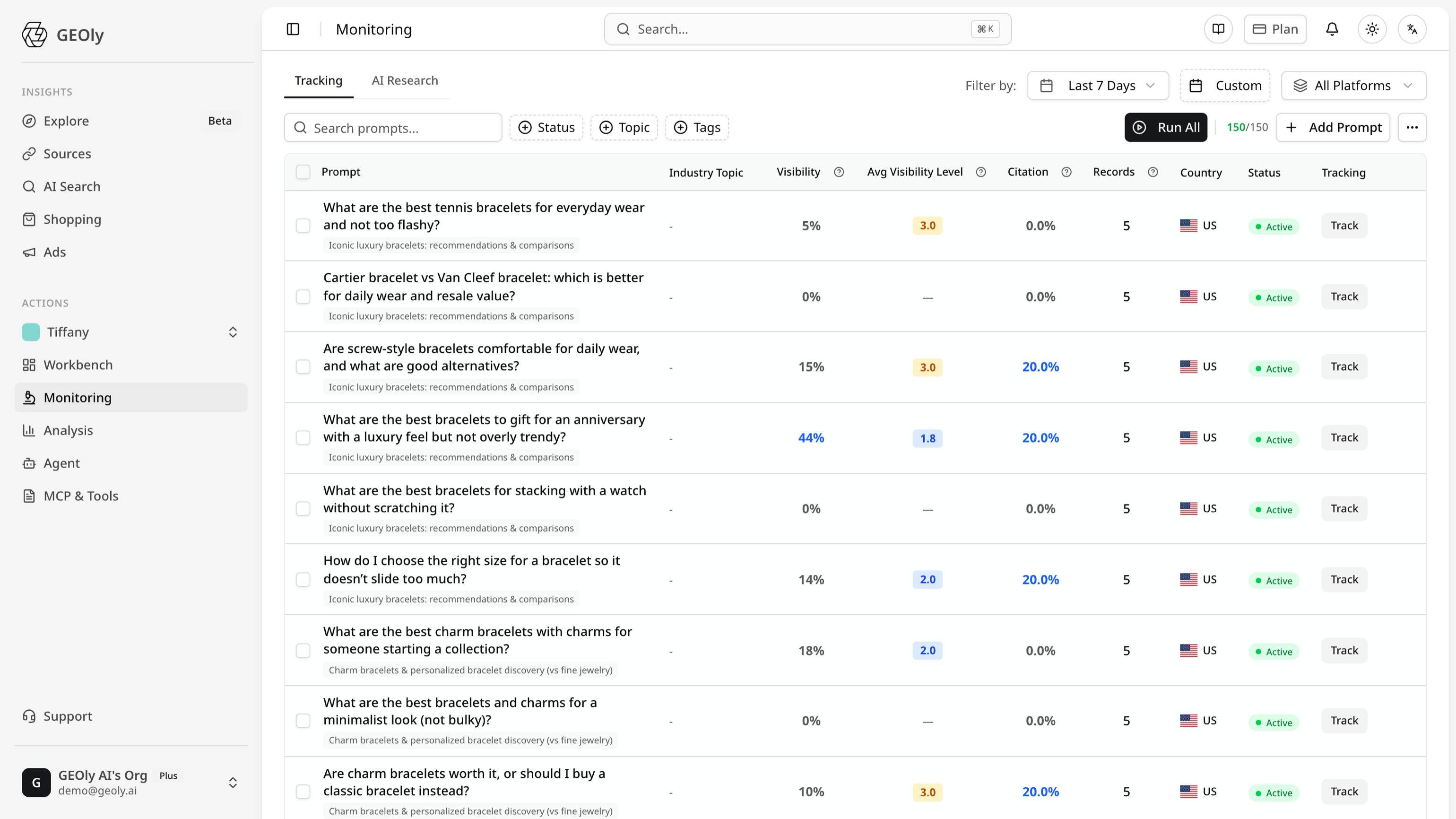
1. 监测 AI 怎么说你
没测量就无法管理。值得追踪的问题是:每个引擎给你贴的是哪些形容词,它会不会提到你的召回或宕机,当消费者问「这个品类最好的选择是什么」时,它推荐的是你还是竞品?
这正是 GEO 平台的价值所在。GEOly AI 跨七个引擎(ChatGPT、Gemini、Perplexity、Copilot、Grok、Google AI Mode、AI Overviews)读取品牌感知,汇总成 0–100 的 AIGVR 可见度分,再加上 Share of Model、提及率与引用率,以及一份声誉看板该有的全套 AI 搜索 KPI。一个下午就能接好,免费试用 3 天。

 — GEOly AI GEO guide cover")
 — GEOly AI GEO guide cover")
